The advent of generative large language models (LLMs), such as ChatGPT, heralds a transformative era across various industries. Their prowess in crafting text that mirrors human interaction has revolutionised domains from automated chatbot services to content generation. Nonetheless, these LLMs are not without their flaws, notably their propensity to produce content that may diverge from factual accuracy or coherence. Enter the Retrieval-Augmented Generation (RAG) framework, a promising solution that merges the robustness of retrieval-based models with the creative flair of generative models, offering a refined method to supply LLMs with contextually pertinent data. In this article, we delve into the workings of the RAG framework and its inherent challenges.
LLM-Powered Chatbot Architecture Explained
Consider a scenario where a data science team is tasked with developing a chatbot to assist financial advisors at a bank. The team has several development paths: constructing an LLM from the ground up, which could be prohibitively expensive, or opting for existing LLM-powered chatbots like ChatGPT, which may not suffice due to limitations such as contextual understanding, domain-specific knowledge gaps, and high operational costs. The RAG framework emerges as the most viable approach under these constraints.
Visualising LLM-Powered Chatbot Architecture Using RAG:
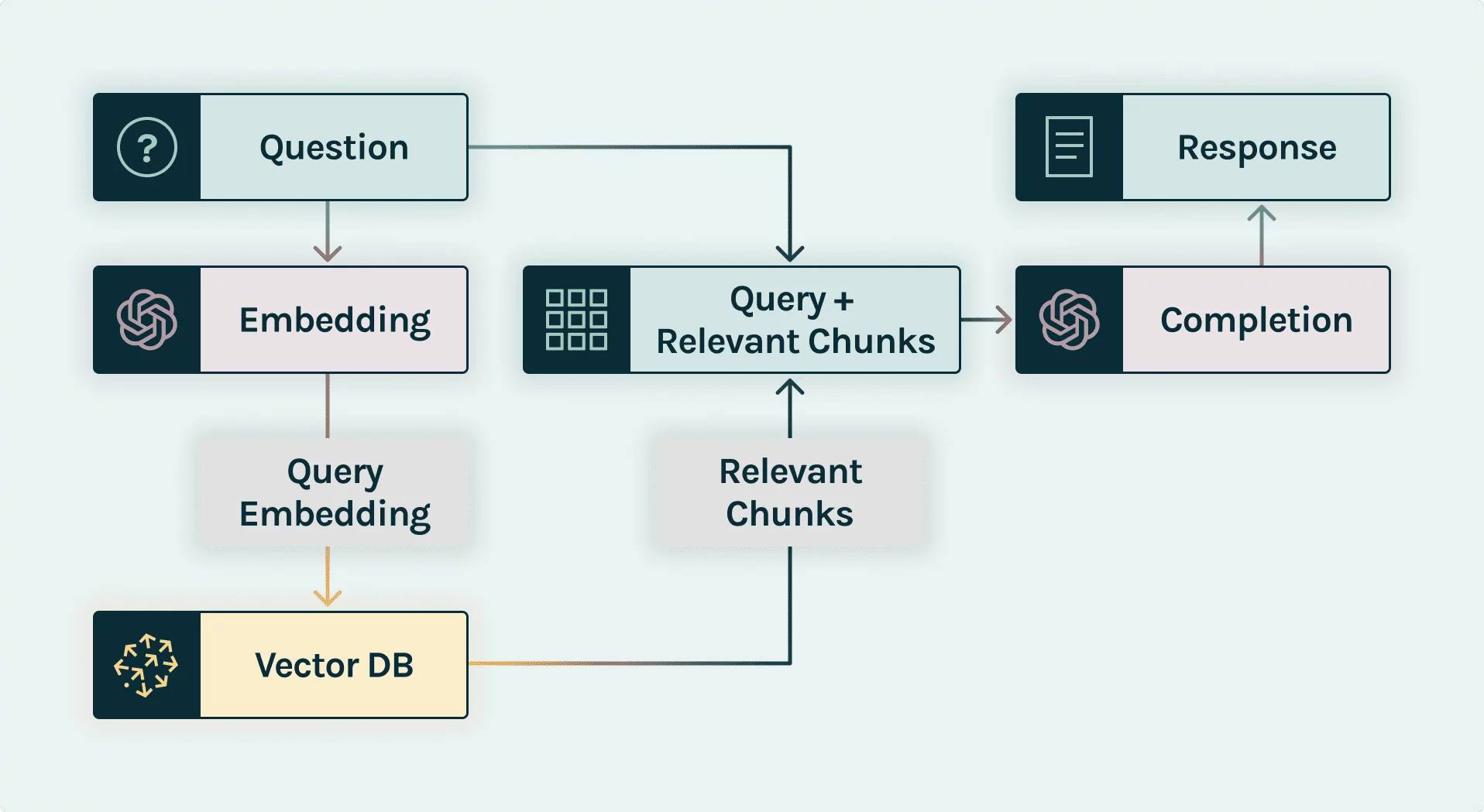
Imagine the following process for generating a response:
- Data Embedding: Company documents are segmented, processed through an embedding model, and stored in a vector database.
- Query Request: A financial advisor queries, for example, the prospects of Apple stock.
- Prompt Construction: An orchestration framework (e.g., Langchain or LLama-Index) is used to embed the query and retrieve the corresponding embedding.
- Prompt Retrieval: A similarity search is conducted across the vector database, identifying the most relevant contexts by cosine similarity, and returning selected documentation snippets.
- Prompt Execution: The chatbot formats the query and retrieved contexts into a prompt, requesting a response from a chat completion API (e.g., GPT 3-5).
- Query Response: The generated answer is relayed back to the financial advisor.
The pivotal element here is the vector database, where documentation vectors are stored and later fetched, ensuring contextually relevant responses.
Challenges of Implementing RAG:
While RAG offers a cost-effective and straightforward enhancement for LLM-powered chatbots, several challenges persist:
- Hallucinations: Although RAG significantly reduces hallucinations, the risk isn't entirely eliminated. Without contextually appropriate data in the vector database, responses might still veer into inaccuracies.
- Fine-tuning Complexity: Balancing the fine-tuning of RAG models is intricate, often necessitating a dataset that marries retrieval and generation tasks, which can be costly and time-consuming to annotate.
- Data Quality and Bias: The efficacy of retrieval models is contingent upon the quality and diversity of the retrieved data. Biased data can skew responses, underscoring the need for unbiased data in the vector database.
- Evaluation Metrics: Traditional metrics like BLEU or ROUGE may not adequately assess the success of RAG systems. Crafting metrics that account for both retrieval and generation is an ongoing endeavour.
Conclusion:
The RAG framework stands as an innovative strategy to bolster the functionality of LLM-powered applications by integrating contextually relevant information, thereby enhancing performance while mitigating hallucination risks. Despite its potential, RAG's imperfections and challenges warrant further refinement. At Sustainability AI, efforts are underway to enhance the observability of Retrieval-augmented Language Models, providing ML teams with the tools to evaluate, monitor, and improve the quality and reliability of LLM-powered applications, ultimately fostering greater trust and efficacy.